
近日,DeepSeek新一代开源模型凭借低成本和高性能引发市场热议,甚至有观点认为其“仅用500万美元就复制OpenAI”,这引发了投资界的恐慌。对此,伯恩斯坦发布报告指出,这种说法是误读。
伯恩斯坦认为,“500万美元”只计算了DeepSeek V3模型基于每GPU小时2美元租赁价格的训练成本,未包含研发、数据及其他费用。
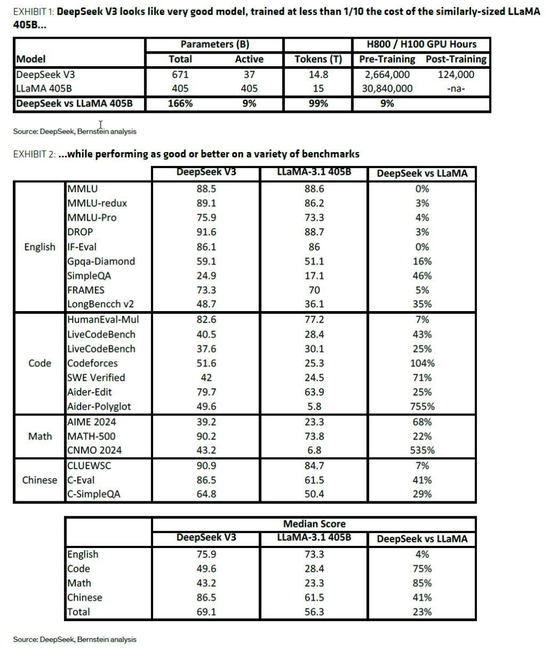
技术层面,伯恩斯坦肯定了DeepSeek在效率提升上的显著进步,但认为并非颠覆性突破。DeepSeek V3模型采用混合专家(MoE)架构、多头潜在注意力(MHLA)技术和FP8混合精度训练,将训练所需算力降低至同等规模开源模型的约9%。虽然效率提升可能超过10倍,但这与业界3-7倍的常见效率提升相比,并非革命性突破。伯恩斯坦表示,MoE架构的重点是降低训练和运行成本,在实际应用中,一次仅激活部分参数。
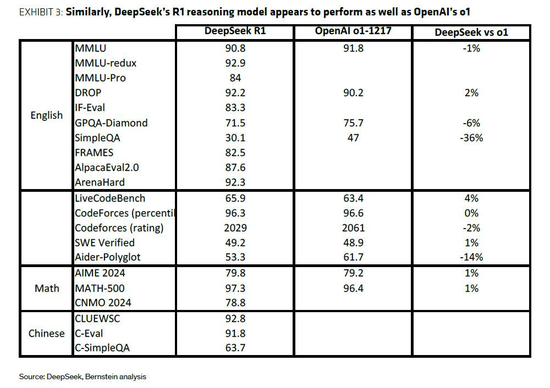
DeepSeek的R1模型则通过强化学习(RL)等技术提升了推理能力,并采用“模型蒸馏”策略,利用R1模型训练更小模型,降低成本。
伯恩斯坦认为,即使DeepSeek实现了10倍效率提升,也仅相当于AI模型当前每年的成本增长幅度。“模型规模定律”下,MoE、模型蒸馏、混合精度计算等创新对AI发展至关重要。基于杰文斯悖论,效率提升通常会带来更大需求,而非削减开支。目前AI计算需求远未触及天花板,新增算力很可能会被不断增长的使用需求吸收。因此,伯恩斯坦对AI板块保持乐观态度。
520新聞:遼港股份股價下跌,主力資金流出,營收淨利雙降現警訊
2025-05-22
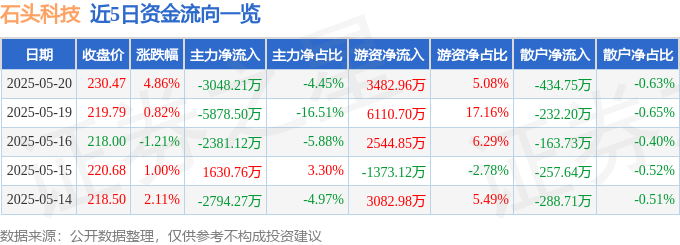
海博思创520股價下跌:主力撤退,散戶接盤?增收不增利风险分析
2025-05-22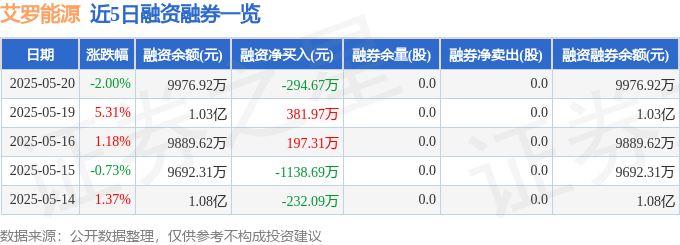
艾罗能源股價520收盤分析:主力撤退?光伏儲能產業前景與風險並存
2025-05-22
520優惠不再?中远海特股價小跌,散戶抄底,主力游资撤退,蘇花公路式风险犹存
2025-05-22
流光飞逝
回复感谢分享DeepSeek的深度分析!伯恩斯坦的报告客观冷静,500万美元成本的误读说明了市场对AI成本的认知偏差。MoE架构和模型蒸馏等技术确实重要,但效率提升并不意味着成本降低,AI算力需求依然巨大,这与我的预期基本一致。
雨夜孤灯
回复感谢分享DeepSeek的分析报告!伯恩斯坦的解读很专业,点明了'500万美元复制OpenAI'的说法过于简化,也客观评价了DeepSeek在技术上的进步和局限性。 MoE架构和模型蒸馏等技术确实值得关注,但正如报告所说,AI算力需求的增长可能抵消效率提升带来的成本降低。总的来说,这篇报道让我对DeepSeek以及AI行业的成本和发展趋势有了更清晰的认识。